R for bioinformatics
Essential facts
R is a powerful and useful statistical software.
R can be downloaded from the internet free.
For many people, R is difficult and frustrating to learn. but the efforts will pay off in the long run.
The graphics are very basic, and not as impressive or professional looking as SPSS output.
I think that the help menu and features are very useful, poignant, and effective.
You cannot learn very much by reading about R. You must spend quality
time practicing, experimenting, and making frustrating mistakes. The language is
rather cryptic and case-sensitive, which causes silly mistakes, sometimes.
R developers are upgrading R at a seemingly fast rate.
As with most object-oriented programming languages, you end up building a very effective and useful library of small to medium programs, subroutines,functions, and other scripts. All of these R scripts can be linked together into a connected routine, which does complicated tasks quickly and correctly.
Learning R is a valuable exercise in logical thinking, problem solving skills buildup, and fundamental current programming experience
------------
R contains most arithmetic functions like mean, median, sum, sqrt, length, log. Many R functions and datasets are stored in separate packages, which are only available after loading them into an R session
library(my_package) # Loads a particular package.
library(help=mypackage) # Lists all functions/objects of a library.
search() # Lists which packages are currently loaded.
Information and management of objects
ls() or objects() # Lists R objects created during session, they are stored in file '.RData' when exiting R and the workspace is saved.
rm(my_object1, my_object2, ...) # Removes objects.
rm(list = ls()) # Removes all objects without warning!
str(object) # Displays object types and structure of an R object.
ls.str(pattern="") # Lists object type info on all objects in a session.
Reading and changing directories
dir() # Reads content of current working directory.
getwd() # Returns current working directory.
setwd("/home/user") # Changes current working directory to the specified directory.
print(ls.str(), max.level=0) # If a session contains very longlistobjects then one can simplify the output with this command. lsf.str(pattern="") # Lists object type info on all functions in a session.
class(object) # Prints the object type. mode(object) # Prints the storage mode of an object.
summary(object) # Generic summary info for all kinds of objects.
attributes(object) # Returns an object's attribute list.
gc() # Causes the garbage collection to take place. This is sometimes useful to clean up memory allocations after deleting large objects.
length(object) # Provides length of object.
.Last.value # Prints the value of the last evaluated expression.
System Commands under Linux
R IN/OUTPUT & BATCH Mode
One can redirect R input and output with '|', '>' and '<' from the Shell command line.
$ R --slave < my_infile > my_outfile # The argument '--slave' makes R run as 'quietly' as possible. This option is intended to support programs which use R to compute results for them. For example, if my_infile contains 'x <- c(1:100); x;' the result for this R expression will be written to 'my_outfile' (or STDOUT).
$ R CMD BATCH [options] my_script.R [outfile] # Sytax for running R programs in BATCH mode from the command-line
Import
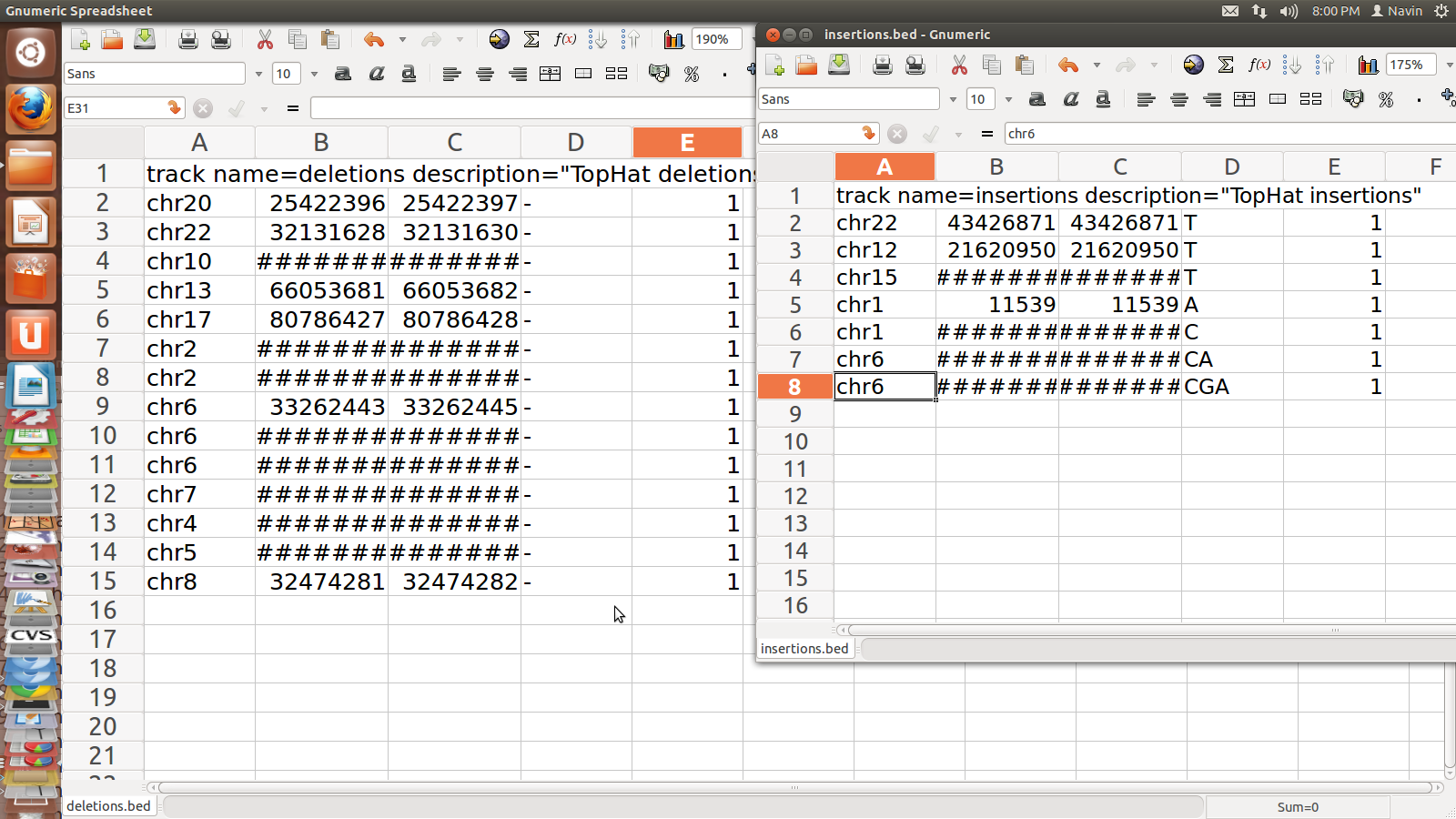
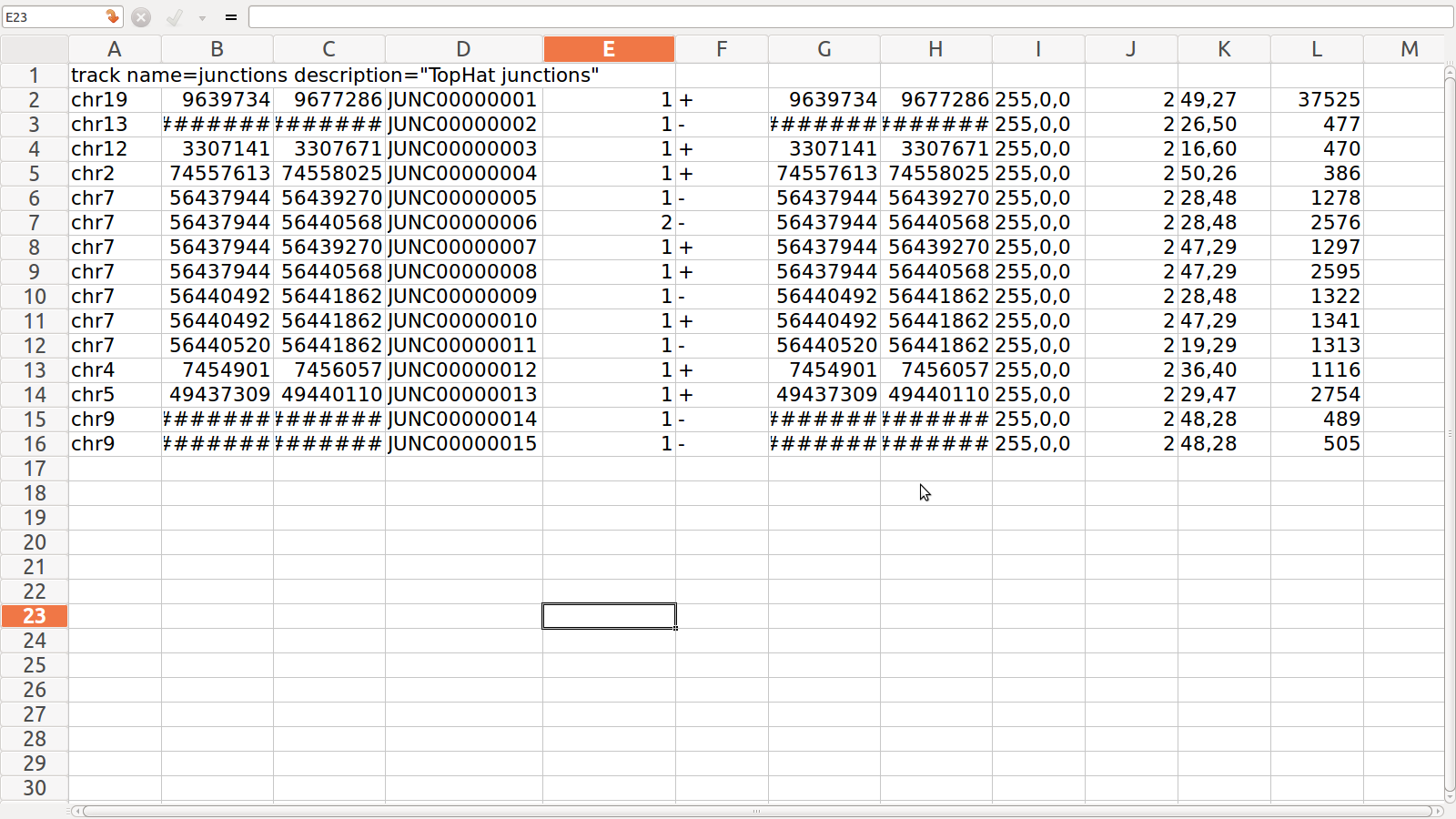
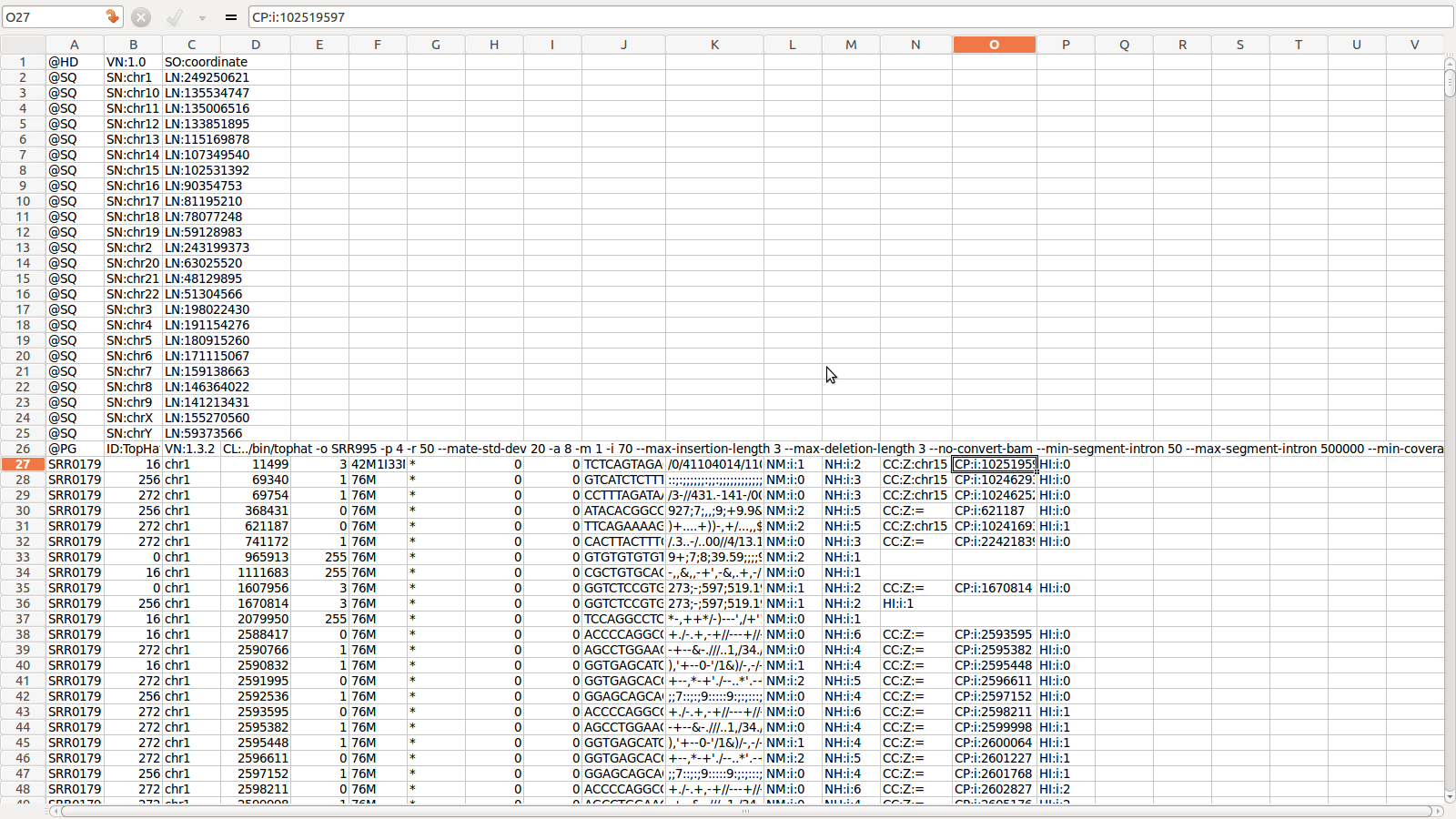
read.delim("clipboard", header=T) # Command to copy&paste tables from Excel or other programs into R. If the 'header' argument is set to FALSE, then the first line of the data set will not be used as column titles.
read.delim(pipe("pbpaste")) # Command to copy&paste on Mac OS X systems.
file.show("my_file") # prints content of file to screen, allows scrolling.
scan("my_file") # reads vector/array into vector from file or keyboard.
my_frame <- read.table(file="my_table") # reads in table and assigns it to data frame.
my_frame <- read.table(file="my_table", header=TRUE, sep="\t") # Same as above, but with info on column headers and field separators. If you want to import the data in character mode, then include this argument: colClasses = "character".
Export
write.table(iris, "clipboard", sep="\t", col.names=NA, quote=F) # Command to copy&paste from R into Excel or other programs. It writes the data of an R data frame object into the clipbroard from where it can be pasted into other applications.
zz <- pipe('pbcopy', 'w'); write.table(iris, zz, sep="\t", col.names=NA, quote=F); close(zz) # Command to copy&paste from R into Excel or other programs on Mac OS X systems.
write.table(my_frame, file="my_file", sep="\t", col.names = NA) # Writes data frame to a tab-delimited text file. The argument 'col.names = NA' makes sure that the titles align with columns when row/index names are exported (default).
save(x, file="my_file.txt"); load(file="file.txt") # Commands to save R object to an external file and to read it in again from this file.
HTML(my_frame, file = "my_table.html") # Writes data frame to HTML table. Subsequent exports to the same file will arrange several tables in one HTML document. In order to access this function one needs to load the library 'R2HTML' first. This library is usually not installed by default.
write(x, file="my_file") # Writes matrix data to a file.
sink("My_R_Output") # redirects all subsequent R output to a file 'My_R_Output' without showing it in the R console anymore.
sink() # restores normal R output behavior.
R Objects:Data and Object Types
Data Types:
Numeric data: 1, 2, 3 ex. x <- c(1, 2, 3); x; is.numeric(x); as.character(x) # Creates a numeric vector, checks for the data type and converts it into a character vector.
Character data: "a", "b" , "c" ex. x <- c("1", "2", "3"); x; is.character(x); as.numeric(x) # Creates a character vector, checks for the data type and converts it into a numeric vector.
Complex data: 1, b, 3
Logical data: TRUE, FALSE, TRUE
1:10 < 5 # Returns TRUE where x is < 5.
Object Types
vectors: ordered collection of numeric, character, complex and logicalvalues. factors: special type vectors with grouping information of its components
data frames: two dimensional structures with different data types
matrices: two dimensional structures with data of same type
arrays: multidimensional arrays of vectors
lists: general form of vectors with different types of elements
functions: piece of code
Factors :Factors are vector objects that contain grouping (classification) information of its components. animalf <- factor(animal <- c("dog", "cat", "mouse", "dog", "dog", "cat")) # Creates factor 'animalf' from vector 'animal'.
animalf # Prints out factor 'animalf', this lists first all components and then the different levels (unique entries); alternatively one can print only levels with 'levels(animalf)'.
animalfr <- table(animalf); animalfr # Creates frequency table for levels.Function 'tapply' applies calculation on all members (replicates) of a level.
weight <- c(102, 50, 5, 101, 103, 52) # Creates new vector with weight values for 'animalf' (both need to have same length).
mean <- tapply(weight, animalf, mean) # Applies function (length, mean, median, sum, sterr, etc) to all level values; 'length' provides the number of entries (replicates) in each level.
Function 'cut' divides a numeric vector into size intervals.
y <- 1:200; interval <- cut(y, right=F, breaks=c(1, 2, 6, 11, 21, 51, 101, length(y)+1), labels=c("1","2-5","6-10", "11-20", "21-50", "51-100", ">=101")); table(interval) # Prints the counts for the specified size intervals (beaks) in the numeric vector: 1:200.
plot(interval, ylim=c(0,110), xlab="Intervals", ylab="Count", col="green"); text(labels=as.character(table(interval)), x=seq(0.7, 8, by=1.2), y=as.vector(table(interval))+2) # Plots the size interval counts as bar diagram.