Tuxedo Suite:
Tophat (alignment to genome)
Cufflinks
(assembling and
counting of genes/transcripts)
Cuffcompare
(compare
gene expression)
Cuffdiff
(differential gene expression testing)
-----------------------------------
Tophat
Purpose: To identify exon-exon junctions
----------------------
Tophat Command
Tophat Options
Junction.BED for SRR995
================

SAM Alignment
SAM for SRR995
Cufflinks
---Options of Cufflinks
 Secrets of FPKM
Secrets of FPKM
-----------------------------------
Tophat
Tophat : maps/aligns RNA seq data to a genome
Note: In order to deal with the problem of splicing in RNA seq data
alignment, you need to use an aligner that is aware of splice junctions
Unique Characteristics: to map
splice junctions de novo, a very handy feature while working on organisms with
incomplete or poorly annotated transcriptomes.(e.g watermelon)
Before Tophat
1. Download species(human)
chromosome file
2. Run the command: > bowtie-build hg19.fa hg19
3. It
will give output index files which should be copied to index folder of bowtie
----------------------
Tophat Command
>../bin/tophat
-o SRR995 -p 6
-r 50 --mate-std-dev 20 -a 8 -m 1 -i 70 --max-insertion-length 3
--max-deletion-length 3 --no-convert-bam --min-segment-intron 50 --max-segment-intron 500000 --min-coverage-intron 50
--max-coverage-intron 20000
--segment-length 25 --keep-tmp --segment-mismatches 2 -I 500000
../hg19 SRR995.fq
•
Note that options are written in red ink
and rest(in blue) are essential.
-----------------------Tophat Options
--output-dir OR -o <filename>: Output location :The default is
"./tophat_out"
--num-threads
OR -p:
number of threads to use
--max-intron-length
OR -i :
Tells tophat to ignore donor/acceptor pairs closer than this many close bases
apart
--min-intron-length
OR -I :
Tells tophat to ignore donor/acceptor pairs farther than this many close bases
apart
-G
<a gtf file>
: tells tophat to use the gtf as a n
annotation reference.
--segment-length
:
each read is cut into this much long segments
-segment-mismatches
:
allows this much mismatches in each segment read alignment
--solexa1.3-quals tells it to use the new illumina
qual values
--keep-tmp: Keep/preserve temporary files
produced during the run.
--no-convert-bam: causes tophat to give SAM file
instead of BAM file
--no-sort-bam: gives output without coordinate
sorting
--min-anchor-length
or -a:
Tells tophat to report junctions spanned by reads with at least this many bases
on each side of the junction.
--splice-mismatches OR -m : max number of mismatches in
the anchor region of a spliced alignment.
--mate-inner-dist
OR -m:
mean distance between mate pairs
--mate-std-dev
O: standard
deviation of distribution of distance between mate pairs.
--no-
discordant :
for paired reads, report only concordant mappings
--max-insertion-length
--max-deletion-length
--segment-length
--min-segment-intron
--max-segment-intron
--min-coverage-intron
--max-coverage-intron
--no-sort-bam
--resume OR -R : tells tophat to
resume in case of failure in the first run
--read-mismatches OR -N : to
ignore those read alignments having more than this much mismatches
--read-gap-length: to ignore
those read alignment having more than this much gap length
--zpacker
OR -z:
to specify that all tmp files are in compressed mode
-z0: to disable compression
---------------------------------------
Tophat Output
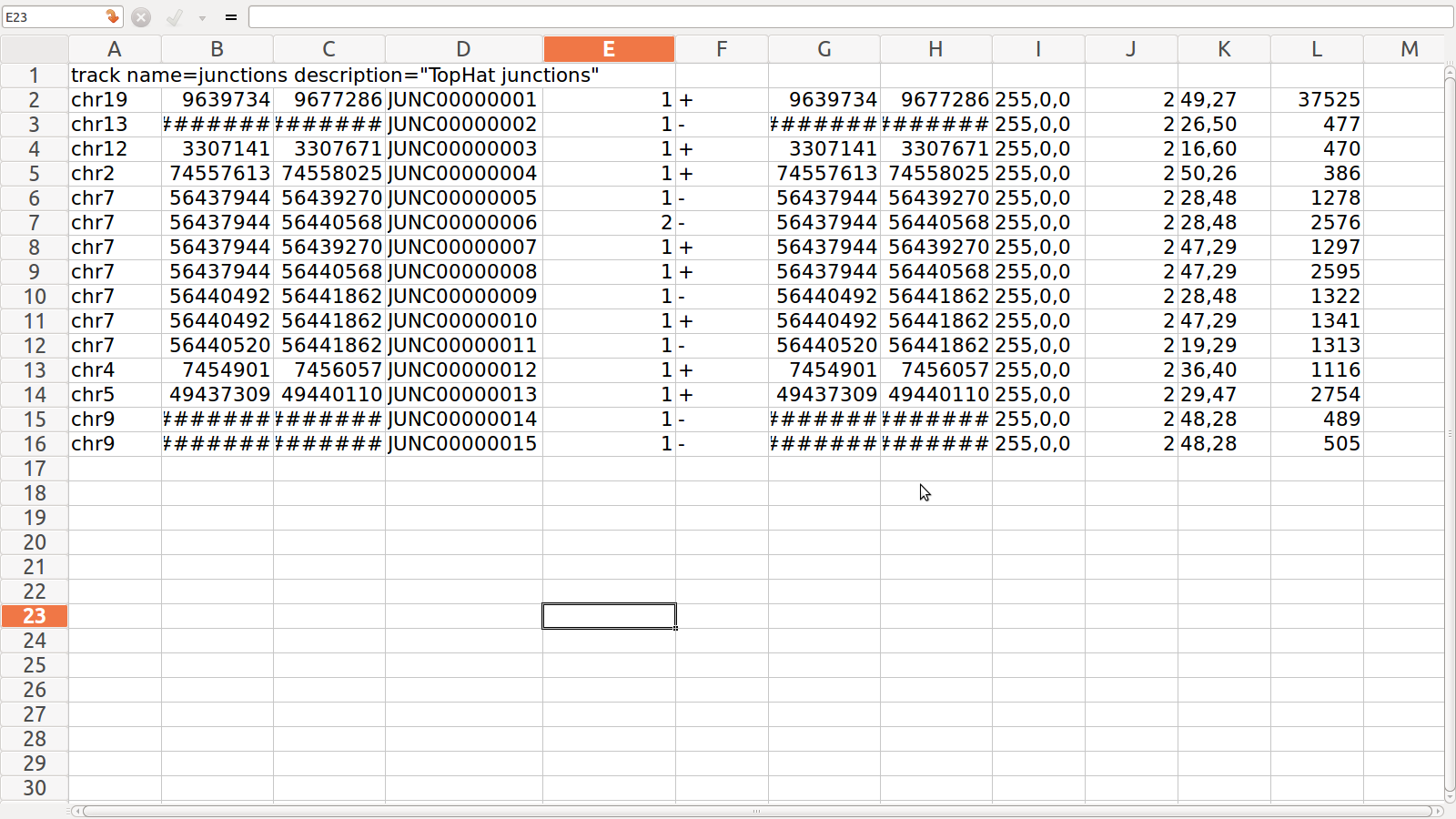
1. junction.bed: it lists BED track of junctions
reported by Tophat where each junction consists of two connected BED blocks
where each block is as long as the max overhang of any read spanning junction
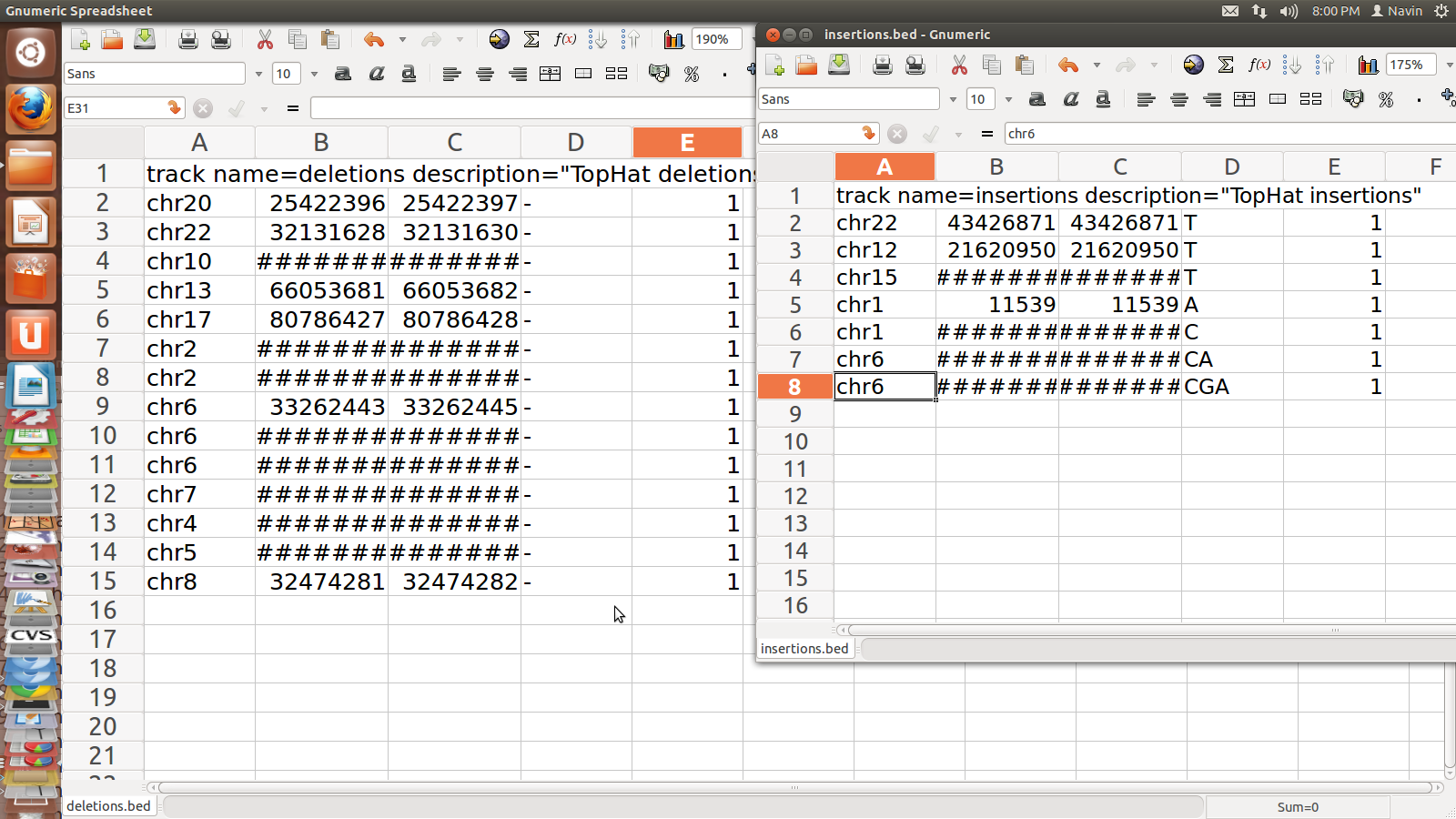
2. deletion.bed: mentions the first genomic base of the
deletion
3. insertion.bed:mentions the last genomic base before
the deletion
4. accepted_hits.bam(/sam):
A
list of read alignments in BAM/SAM format
Let us explore SAM file format in coming
slides
---------------
Insertion.bed
and Deleton.bed for SRR995
Junction.BED for SRR995
================
SAM Format
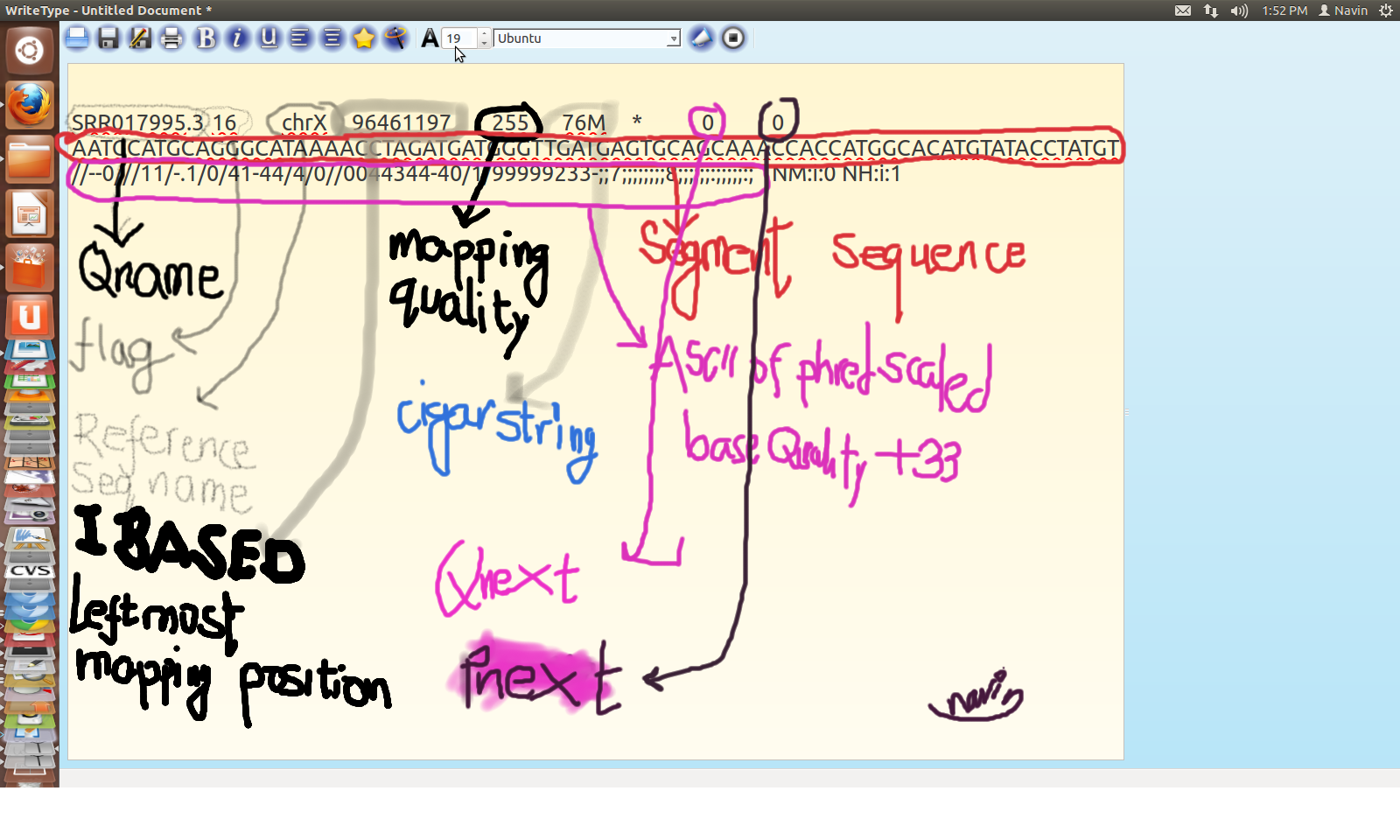
A generic file format for storing large nucleotide sequence alignment in compact manner.
It is marked for
a. flexibility to store alignment from various aligners
b. easy creation from aligners and also convertibility from other other file formats
c. capacity to allow operations on alignment to work on stream without loading whole genomic data
d. allows the file to be indexed on genomic position
Structure of SAM
SAM Alignment
SAM for SRR995
Cufflinks
Cufflinks assembles transcripts, estimates their abundances and tests for differential expression and regulation.
Cufflinks module consists of cufflinks, cuffcompare and cuffdiff (and cuffmerge) commands
It accepts aligned RNA seq read alignment and assembles into a parsimonious set of transcripts
It estimates relative abundances of each transcript. It is based on how many reads support each transcript
---Options of Cufflinks
cufflinks [options]* <alignedreads.bam or .sam>
SAM is a standard short read alignment that allows aligners to attach custom tags to individual alignments and Cufflinks requires that alignments have some of these tags
Option : -g (or -G) species.gtf is a must As this is an annotation file where all genes/transcripts of the species have ids and tags.(Identity Collection)
-G <reference annotation gtf file> : to estimate isoforms abundances but ignore novel ones
-g <reference annotation gtf file> : to estimate isoforms abundances as well as novel ones
- p and -o are have the same meaning as that in tophat.
-M OR --mask-file:Tells cufflinks to ignore those reads which could have come from the specified transcript file
-b OR --frag-bias-correct: frag bias correct : torun bias detection and correction algorithm so as to improve accuracy of transcript abundance estimates
-m OR --frag-len-mean : average fragment length: The default is 200bp
-s OR --frag-len-std-dev : standard deviation of distribution of fragment length : Default is 80bp.
-N OR --upper-quartile-norm : normalized by upper quartile to improve robustness of differential expression calls for less abundant genes and transcripts
Note: Cufflinks now learns the mean and std dev of fragment length for each SAM file so using options -m and -s is no longer recommended
--total-hits-norm: to count all fragments
--compatible-hits-norm: to count fragments comptible with reference annotation
--max-mle-iterations : to set number of iterations allowed during max likelihood estimation of abundances
-p , -o, -G have same meaning as that in Tophat options
Cufflinks Output
1. transcripts.gtf
Column number
|
Column Name
|
Example
|
Description
|
1
|
seqname
|
chr
|
chromosome name
|
2
|
source
|
cufflinks
|
program which generated
|
3
|
feature
|
exon
|
type of record: either transcript or exon
|
4
|
start
|
455666002
|
leftmost coordinate of this record
|
5
|
end
|
455666978
|
rightmost coordinate of this record
|
6
|
score
|
455666978
|
strnd from which the isoform came from
|
7
|
strand
|
+/-
| |
8
|
frame
|
.
| |
9
|
attributes
|
see the next page
|
Attributions of GTF file
1.gene_id
2.transcript_id
3. FPKM
4. frac
5. conf_lo: Lower bound of the 95% confidence interval of the abundance of this isoform, as a fraction of the isoform abundance is determined from this number
6.conf_hi: Upperbound of the 95% confidence interval of the abundance of this isoform, as a fraction of the isoform abundance is determined from this number
7. cov: Estimate for the absolute depth of read coverage across the whole transcript
8. full_read_support
2. isoform.fpkm_tracking: This file contains estimated isoform level expression levels in FPKM tracking format
3. genes.fpkm_tracking: This file contains estimated gene level expression levels in FPKM tracking format
-------
Glimpse of one row of gtf file
Secrets of FPKM- FPKM : a measurement of pair of transcript reads that has been normalized both for transcript length and for the total number of mappable reads from an experiment.
- This normalized number helps in the comparison of transcript levels both within and between samples.
-------
Cuffcompare
It takes Cufflinks GTF output as input and optionally can take a reference annotation and gives 5 output files including combined.gtf which contains union of all transflags. If a transflag is present in both samples, it is thus reported once in the combined gtf.
It helps analyze the transflags we assemble
It compares the assembled transcripts to the reference annotation
It tracks cufflinks transcripts across different experiments.
Run the command as
cuffcompare [options]* cuff1.gtf cuff2.gtf cuff3.gtf
where cuff?.gtf are outputs of cufflinks
Cuffcompare Options
-r : An optional annotation reference file. Each sample is matched against this file and sample isoforms are tagged overlapping or matching or novel one depending on case.
-R : it tells the cuffcompare to ignore those reference transcripts which are not overlapped by any transcript of any sample gtf
-s : causes cuffcompare to look into fasta files with the underlying genomic sequences against which your reads were aligned for some optional classification function.
-V: verbose: it will write what cuffcompare is doing and also showing any warning
-o: Directory of output file :
-r :tells it to use annotation.
-R ; tells it to leave out transcripts not present in any sample
-s: switch for some reason is necessary to propagate the gene names through to the next step properly.
No comments:
Post a Comment